伪随机算法系列-01 Hashing(Small xxHash)
翻译—-Pseudorandom Noise-Hashing
如果你觉得这篇教程不错,请去支持原作者
此教程使用的Unity版本为2020.3.6f1
- 创建一个可视化Hash网格
- 把2D坐标转换成伪随机值
- 实现一个小型的xxHash算法
- 使用该Hash算法计算方块位置和颜色
这是Basics系列之后的第一个伪随机噪声的系列教程.教大家如何使用一种小型特化版的xxHash函数来生成伪随机数.

1 可视化(Visualization)
随机可以让事情变得不可预测,多变以及出现得更加自然.不论我们感受到的是真正的随机,还是由于信息的不对称感觉到的随机,还是由于我们自身观察到结果后理解的随机,都不重要,只要是像随机就行.所以我们为何不能使用一种完全确定的随机序列呢?因为只要使用的人觉得随机就行了.垃圾的多线程设计可以产生莫名其妙的随机效果,但是这个方法太不稳定了,没有意义.真正的随机只存在于非计算机环境中,比如采集大气噪声得到的结果.但是这些东西基本用不上.
在开发中,真随机基本都是用不到的.因为它产生的事件真的独一无二无法控制.我们真正需要的是一个可以得到固定随机值的算法,也就是可预测随机数.这就是使用Hash的原因.
这个教程将教大家创建一个用许多Cube建立的2D网格,看上去就像一个可视化的Hash函数.就像Basics教程教的一样,我们建立一个新的工程项目,因为要使用Job系统,先导入Burst包.我还将使用URP,所以还需要导入Unity的UniversalRP包.
1.1 Hash Job
我们使用Unity的Job功能来创建一个HashValue的生成器.就像Basics教程里面说的那样,首先创建一个名叫HashVisualization的组件类,里面包含一个Job.使用这个HashJob填充NativeArray.
HashValues本质上是一组没有内在意义的值.我们使用uint这个类型,因为它可以包含32位4字节整形的最大值.现在只是用Job的Execution Index来作为最初的HashValue.
1 | using Unity.Burst; |
为什么不是用int作为HashValue的类型? 因为int是有符号整形,最高位是用来判断正负的,并不是用来实际计数的,在底层计算中这一位的计算方式和其他位不一样.
1.2 初始化与渲染(Initialization and Rendering)
就如同在Basics教程中一样,我们在HashVisualization类中声明以下内容(_Hashes和_Config是在Shader注册的ID)
1 | static int hashesId = Shader.PropertyToID("_Hashes"); |
OnEnable函数中初始化所有的内容,为了填充Buffer数据,我们需要运行一次HashJob以便得到初始的数据,这样就不用每帧都来一遍.因为还需在Shader中操作分辨率(resolution)相关的内容,所以需要传入resolution的值以及它的倒数1/resolution的值.
1 | void OnEnable() |
OnDisable函数中清理数据,OnValidate函数中进行重置操作以便在播放模式下可以刷新Mesh数据.
1 | void OnDisable() |
现在我们只需要在Update中不断绘制数据就行了.这个做法将网格塞在了原点的一个方块当中.
1 | void Update() |
1.3 着色器(Shader)
使用HLSL语法写一个如下的Shader,与Basics的早期版本不同之处在于,我们直接使用实例的ID(unity_InstanceID)来计算坐标.
为了将1D的线转换成2D的格子,需要将其等分切断,依次排好后在第二个维度上平移^1.我们可以用实例的ID除以分辨率(1/resolution * unity_InstanceID),不过GPU并没有整数除法,可以通过floor函数来抛弃小数部分从而得到结果.这个结果V,是第二个维度上的坐标(可以理解成Y),U坐标(可以理解成X)是通过ID减去V坐标乘以分辨率(resolution)计算得到的.
然后我们使用UV坐标将这个实例放在XZ坐标平面上,平移缩放将其保持在原点的Cube内.
1 |
|
然后使用下面的方法来查找Hash值,并用它来计算RGB值.通过将hash值除以分辨率的平方,可以得到由黑到白的渐变效果.
1 | float3 GetHashColor() |
接下来的函数是用于计算颜色和位置的
1 | void ShaderGraphFunction_float(float3 In, out float3 Out, out float3 Color) |
就如同Basics里教的一样,创建一个ShaderGraph文件.不过我们使用了新的HLSL文件和方法,并且直接将我们计算的color赋给片段着色器.并且使用默认值0.5来保证平滑度,而不是让其可以被动态设置.
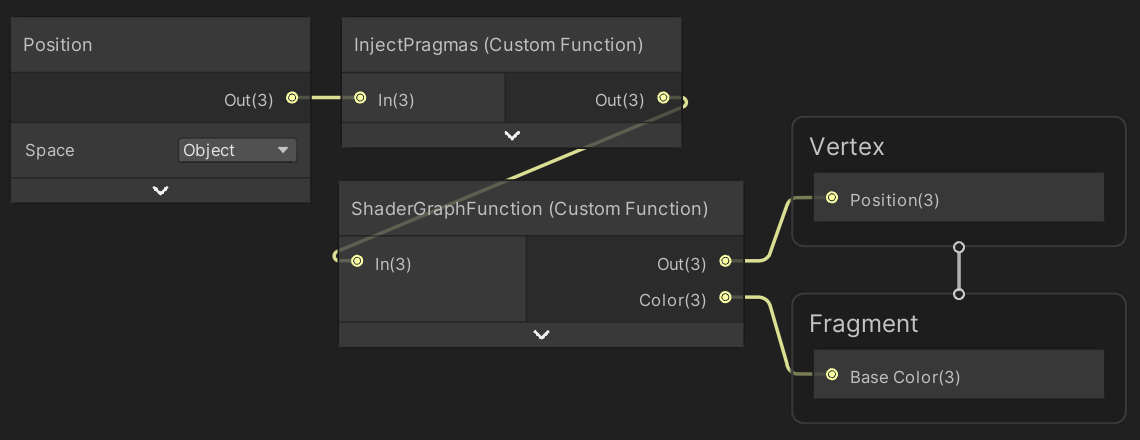
下面的代码是InjectPragmas函数节点的内容
1 |
|
为什么我没有使用URP? 你当然也可以使用URP,或者创建一个使用HLSL语法,包含默认RP的Surface Sharde.就如同Basics教程里写的那样.
现在我们可以创建一个使用我们自己shader的material,再创建一个GameObject并挂上HashVisualization脚本,并且设置好material和instance mesh.
此时在Unity的PlayMode中应当可以看到如下效果

在PlayMode下通过调整分辨率滑块可以动态生成不同分辨率下的网格效果.在绝大多数情况下这种方式是没问题的,但是在小部分情况下会出现网格没有对齐的现象

这个错误是由于float的浮点精度限制造成的.在某些情况下,在调用floor之前,我们会得到一个稍微小于整数的值,这会造成实例被放置到错误的位置上.在我们的项目中,可以在丢弃小数之前,简单地通过加0.00001来解决这个问题.
1 | float v = floor(_Config.y * unity_InstanceID + 0.00001); |
1.4 模式(Patterns)
在真正的实现Hash函数之前,让我们先考虑一下简单的数学问题.第一步,需要让灰度值被限制在256个单位的范围内.在GetHashColor函数中,使用255(也就是11111111这个二进制掩码)和_Hashes[unity_InstanceID]进行与(AND)运算,从而屏蔽掉了8位以上的值,只保留uint中最低8位的值,将值限制在了[0,255]这个范围内.然后通过除以255来归一化到[0,1]之间.
1 | uint hash = _Hashes[unity_InstanceID]; |
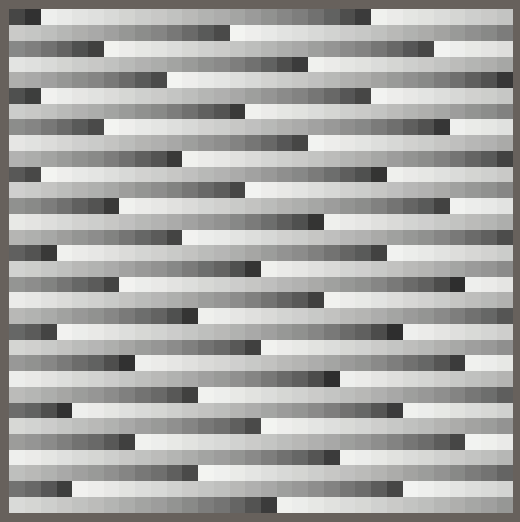
渲染的效果取决于分辨率(resolution).分辨率为32时,我们得到了一个在Z方向上重复4次的灰度效果.分辨率为41时,就会变成倾斜的效果.
 |
 |
|---|
让我们用Weyl序列算法替换简单的渐变算法,就像我们在Organic Variety教程中最初用来给分形上色一样.在HashJob类的Execute方法中,我们将frac计算结果乘以256f,从而得到了在[0,255]的之间的hash值.
1 | hashes[i] = (uint)(frac(i * 0.381f) * 256f); |
 |
 |
|---|
我们发现现在的效果还是有明显的重复,方向取决于分辨率.为了使效果不依赖分辨率这个值,我们必须将函数建立在点的UV坐标上,而不是索引上.所以可以把计算坐标的操作移动到Job中,就像我们在Shader中做的那样,用U和V作为序列的基进行计算,不过还需要添加分辨率及其倒数的字段.
1 | public int resolution; |
我们能用整数除法来代替floor方法吗? 可以,但是这不是一个好主意.因为整数除法不能向量化,这会使计算效率降低.你可以研究Burst生成的代码来验证这一点.
Note that the SSE2 instruction set doesn’t include a vectorized floor operation, so when limited to that instruction set you get four un-vectorized calls to a floor function instead, which is suboptimal. Because in this specific case we’re only dealing with positive values you could also cast to an integer instead, which does vectorize with SSE2. But I ignore this to keep things consistent.
把修改后的数据填到OnEnable函数中的HashJob上
1 | new HashJob |
 |
 |
|---|
现在我们得到了一个更有趣的效果,看起来比以前更随机,但它也有非常明显的重复.为了得到更好的效果,我们需要一个更好的哈希函数.
2 Small xxHash
Hash函数有很多,不过我们不需要那些用于数据加密级别的Hash函数.我们需要的是快速而又能产生不错效果的.Yann Collet的xxHash算法就是一个非常不错的选择.因为我们的数据输入量非常的小,只有2个Int,所以我写了一个XXH32的改版,跳过了原本算法的2,3,4步.我将它命名为SmallXXHash.
2.1 Hash Struct
创建一个结构体SmallXXHash.定义如下5个const变量.这是5个2进制质数,用于后续的位运算.是由Yann Collet精细挑选而来的.
1 | public struct SmallXXHash |
该算法通过将hash bits存储在累加器中来工作,因此需要一个uint字段.创建此算法的第一步就是写一个带参构造函数,用Seed+primeE将accumulator初始化.我们将Seed强转为uint.不过由于int在代码中更常用,所以Seed被声明为int类型.
1 | uint accumulator; |
How is a constructor method defined? It is declared as a regular method that returns the type that it constructs, except that it doesn't have a name. It also doesn't explicitly return anything, because the method is always used to initialize a new object instance or struct value.
初始化之后,我们有了一个计算过的SmallXXHash值.为了得到最终结果,用下述方法来直接返回accumulator.
1 | public uint ToUint() => accumulator; |
不过我们可以通过隐式转换更加方便的得到这个值,重载隐式转换操作符.
1 | public static implicit operator uint (SmallXXHash hash) => hash.accumulator; |
现在我们可以在Job中创建一个新的SamllXXHash值,并且使用0作为初始种子,便可以隐式转换赋值给hashes.
1 | public void Execute(int i) |
2.2 Eating Data
XXHash32算法同时处理输入数据的32个位.而我们的小型版只消化掉1位.在SmallXXHash类中建立一个返回void的Eat(int)方法,同样使用int作为形参并且在计算时强转为uint,然后将其与配置参数primeC相乘,接着再加到accumulator中.这种做法会导致int类型的数据溢出,但是无所谓,因为得到什么样的值都可以.所以所有的操作得到的都是232的有效模.
1 | public void Eat(int data) |
接下来修改代码,在Execute处理U,V两个值.
1 | public void Execute(int i) |

这是Eat操作中的第一步.我们还需要将累加之后的值进行一个比特位上的旋转.添加一个下面的静态私有方法来,使用左移<<操作符来旋转.
1 | private static uint RotateLeft(uint data, int steps) => data << steps; |
位移运算是如何进行的? Bit位依次左移,不够的位补0, 例如
0b11111111_00000000_11111111_00000001 << 3 后,等于 0b11111000_00000111_11111000_00001000
旋转与位移的区别就是,旋转是要把位移之后丢失掉的bit位在另一边重新填上.对于32位的数据,可以通过32减去移动的位数得出反向移动的长度来得到另一边的数据,然后执行或运算进行补齐.
1 | private static uint RotateLeft(uint data, int steps) => (data << steps) | (data >> 32 - steps); |
CPU里没有自带左旋转指令集? 有,Burst编译器会自动识别这种代码进行优化.但是在编码过程必须得像上面那样写.
现在在Eat中将accumulator左移17位,然后右移15位,再或到一起.这样做的好处是避免了单纯+-型的数学运算,Burst编译器也会对此函数做内联处理,速度更快.
1 | public void Eat(int data) |
Eat操作的最后一步就是将上面计算好的值与primeD相乘
1 | public void Eat(int data) |

虽然这么做之后,效果看上去也不尽人意,但Eat的内容就是这样了.我们再添加它的另一个变种方法,虽然在这个教程中并不会使用这个变种.这个新的Eat用来处理byte数据,就像XXHash32原版那样,这次是移动11位,并且与primeE和primeA相乘.
1 | public void Eat(byte data) |
2.3 雪崩效应(Avalanche)
XXHash算法的最后一步就是要打乱accumulator参数的bit位,分散输入数据对bit位的影响.
这就是雪崩效应.我们在Eat掉所有数据之后,最后强转为uint的阶段来做这个操作.
雪崩算法开始于我们的最终累加值,先右移15位后与原始数据^运算.然后乘以primeB,再右移13位后与上一步的数据^在一起,接着乘以primeC,最后右移16位后与上一步数据^.
1 | public static implicit operator uint(SmallXXHash hash) |
What does bitwise XOR do? It is the eXclusive bitwise OR operator. Each bit becomes 1 when either the first or the second operand has the same bit set to 1. When both or neither operand bits are 1 the bit becomes 0.
For example, 0b00111100 ^ 0b00001111 yields 0b00110011.
不翻译了,这是位运算中异或运算的规则
 |
 |
|---|
2.4 负坐标(Negative Coordinates)
为了让我们的算法同样适用于负坐标,必须要将UV值减去一半.修改HashJob.Execute函数如下.
1 | int v = (int)floor(invResolution * i + 0.00001f); |
 |
 |
|---|
现在修改分辨率时Hash的效果将居中对齐,不过分辨率在奇数和偶数间切换的时候会有小幅度的抖动.
2.5 链式调用(Method Chaining)
虽然SamllXXHash的功能已经完成了,但是我们还可以修改一下加入链试调用使使用更加方便.修改Eat方法使其返回类本身来达到这个效果.
1 | public SmallXXHash Eat(int data) |
然后将代码修改成如下调用方式.这样就只需要一排代码就能完成所有的计算.
1 | //var hash = new SmallXXHash(0).Eat(u).Eat(v); |
2.6 不变性(Immutability)
我们可以继续修改一下SamllXXHash类,确保Eat方法在调用时不会改变它内部的值.这样我们就能保存计算的中间值以方便后面的计算.把SamllXXHash改成只读模式,使它的行为看上去更像一个单纯的值.
添加上只读操作符.
1 | public readonly struct SmallXXHash { … } |
accumulator也要只读.
1 | private readonly uint accumulator; |
现在修改accumulator的唯一方法就是通过构造函数.因为readonly关键字修饰的参数只能在构造函数里赋值.修改一下构造函数变成单纯的赋值而不是计算种子.
1 | public SmallXXHash(uint accumulator) |
现在我们有了一个将uint转化成SmallXXHash类的方法,建立一个隐式转换来方便操作.
1 | public static implicit operator SmallXXHash(uint accumulator) => new SmallXXHash(accumulator); |
Eat方法现在就可以直接返回新生成的SmallXXHash对象了.
1 | public SmallXXHash Eat(int data) => RotateLeft(accumulator + (uint)data * primeC, 17) * primeD; |
最后为了可以使用Seed来初始化SmallXXHash,需要增加一个静态的方法来创建新的hash值对象.
1 | public static SmallXXHash Seed(int seed) => (uint)seed + primeE; |
用现在的新方式来初始化Hash值就不需要显示调用构造函数了,只需要调用一个静态方法链就行了.修改HashJob.Execute如下.
1 | hashes[i] = SmallXXHash.Seed(0).Eat(u).Eat(v); |
请注意,这些写法完全是为了装逼,编译器最终生成的代码不会有任何区别.
3 更多关于Hash的东西(Showing More of the Hash)
SmallXXHash类做完了,现在轮到讨论生成效果的时候了.
3.1 用不同的bit位(Using Different Bits)
到目前为止,我们只看过了处理低8位数据后的Hash效果图.通过在GetHashColor函数中简单的对hash进行位移操作,就可以看到处理第二个字节后生成的效果了.
1 | return (1.0 / 255.0) * ((hash >> 8) & 255); |
|
 |
|---|
通过这种移位的方法,我们能只用一个Hash流程创造4种完全不同的计算效果(因为一个uint32有4字节32位).当然你也可以使用其他的位移量来达到相同的Hash流程.
3.2 上色(Coloring)
我们可以通过组合hash值上的3个字节来组成RGB颜色通道上的3位数据.最低位作为红色R,第二位作为绿色G,第三位作为蓝色B.所以需要对hash右移0位,右移8位和右移16位.
1 | uint hash = _Hashes[unity_InstanceID]; |

3.3 可配置的Seed(Configurable Seed)
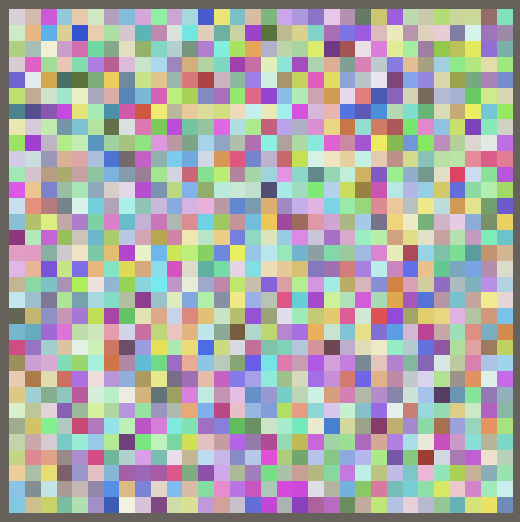
现在有了一个可以把hash值可视化75%的效果了.接下来我们把seed参数设计成可配置的模式.在HashJob里修改代码变成如下.
1 | public int seed; |
再HashVisualization类中添加一个Unity属性来修饰seed字段使它可以自由的编辑.然后赋值到HashJob类中.
1 | [SerializeField] |

现在你可以通过修改Seed参数来创建不同的Hash效果了,而且他们看起来都是完全不一样的.
 |
 |
|---|
我们还能更进一步,将SamllXXHash的初始化拿到Job外面去,这样就不用每次Execute都新建一个了,除了速度上的优势,你还能在程序进到Job之前就设定好你需要的seed.
在HashJob中移除seed字段,然后添加一个SamllXXHash结构体的字段hash.然后修改Execute的对应部分.
1 | //public int seed; |
在OnEnable函数中把Seed传进去初始化hash.
1 | new HashJob |
3.4 用上最后一个字节(Using the Last Byte)
我们生成的hash值到这里还剩一个byte没有被可视化,可以把它用在不透明度(opacity)上,但是这样会让显示效果很难被看清,还需要考虑透明通道渲染深度的排序问题.所以我们决定用这一字节来做垂直方向上的位移效果(偏移Z轴).
把垂直偏移量设计为可配置模式,设定范围(-2f, 2f],默认值为1.我们让这个偏移量相对于Cube的大小,所以需要除以分辨率(resolution).然后把这个计算后的结果作为Shader参数vector4中的第三个数据传入.
1 | [SerializeField, Range(-2f, 2f)] |
在Shader中的ConfigureProcedural函数里面应用计算好的Hash值.最后一个字节是通过把hash值向右移动24位得到的,位移之后其他的位会自动填9补齐,所以我们就不用特意处理它们了.接下来把这个值乘以(1.0/255.0)归一化到[0,1]之间,然后再减去0.5归一化到[-0.5,0.5]之间.
1 | unity_ObjectToWorld._m03_m13_m23_m33 = float4( |


伪随机算法系列-01 Hashing(Small xxHash)
https://tzkt623.github.io/2022/01/05/Pseudorandom Noise-01 Hashing/
